Most scientific data analyses comprise analyzing voluminous data collected from various instruments. Efficient parallel/concurrent algorithms and frameworks are the key to meeting the scalability and performance requirements entailed in such scientific data analyses. The recently introduced MapReduce technique has gained a lot of attention from the scientific community for its applicability in large parallel data analyses. Although there are many evaluations of the MapReduce technique using large textual data collections, there have been only a few evaluations for scientific data analyses. The goals of this paper are twofold. First, we present our experience in applying the MapReduce technique for two scientific data analyses: (i) High Energy Physics data analyses; (ii) Kmeans clustering. Second, we present CGL-MapReduce, a stream based MapReduce implementation and compare its performance with Hadoop.
The paper accepted for the eScience 2008.
Monday, November 17, 2008
Friday, October 10, 2008
Multi Dimensional Scaling (MDS) using MapReduce
As part of my ongoing research on various parallelization techniques, I implemented a MapReduce version of a MDS program. My colleague Seung-Hee Bea has developed the in memory implementation of MDS using C# which runs on a multi-core computers. As the first step in converting that algorithm to a MapReduce implementation, I implemented a single threaded version of the same program in Java (since I am planning to use CGL-MapReduce as my MapReduce runtime). I ran this program to reduce 1024 four dimension (4D) data set to a 3D data set and measured the execution time of the different parts of the program. The result showed that 97.7% of the overall execution time of this program is used for matrix multiplication (both square matrices and matrix and vector multiplications).
This observation motivated me to first implement the matrix multiplication in MapReduce and parallelize the matrix multiplication part of the entire computation using MapReduce technique. I developed both square matrix and matrix and vector multiplication algorithms using CGL-MapReduce and incorporated these to the MDS algorithm.
I tested this MapReduce version of the MDS program using 1024 and 4096 points data sets (4 dimensional data reduced to 3D data) and obtained the following results. The data I used has a predefined structure and the results show the exact structure of the data. In addition the results also tally with the results of the single threaded program. So I can reasonably assume that the program performs as expected. The program performed the MDS on 1024 data set in nearly 11 minuites and the 4096 data set in 2 hours and 40 minuites.
I tested this MapReduce version of the MDS program using 1024 and 4096 points data sets (4 dimensional data reduced to 3D data) and obtained the following results. The data I used has a predefined structure and the results show the exact structure of the data. In addition the results also tally with the results of the single threaded program. So I can reasonably assume that the program performs as expected. The program performed the MDS on 1024 data set in nearly 11 minuites and the 4096 data set in 2 hours and 40 minuites.

Figure 1. Resulting clusters of Multi Dimensional Scaling. Left hand side images shows the clusters visualized using MeshView software and the right hand side images illustrate the predefined structure expected in the data set using lines drawn on the same image.
Memory Size Limitation
The current MapReduce implementation of the MDS algorithm handles only the matrix multiplication in the MapReduce style. However, I believe that we can come up with a different algorithm which will allow most of the computations performed in MDS to be performed using MapReduce. This will reduce the amount of data that needs to be held in-memory by the master program allowing the MDS program to handle larger problems utilizing the total memory available in the distributed setting.
Wednesday, August 20, 2008
Hadoop as a Batch Job using PBS
During my previous data analyses using Hadoop and CGL-MapReduce I had to use the compute resources accessible via a job queue. For this purpose I used the Quarry cluster @ Indiana University which support batch job submissions via Portable Batch System(PBS). I contacted one of the system administrators of the Quarry (George Wm Turner) and he point me to the Hadoop On Demand (HOD) project of Apache which mainly try to solve the problem that I am facing.
We gave HOD a serious try but could not get it working the way we wanted. What we tried was to install HOD in set of nodes and let users to use it on demand via a job queue. This option simply did not work for multiple users, since the configurations options for the file system overlap between the users causing only one user to use Hadoop at a given time.
With this situation, I decided to give it a try to start Hadoop dynamically using PBS. The task the script should perform is as follows.
1. Identify the master node
2. Identify the slave nodes
3. Update $HADOOP_HOME/conf/masters and $HADOOP_HOME/conf/slaves files
4. UPdate the $HADOOP_HOME/conf/hadoop-site.xml
5. Cleanup any hadoop file system specific directories created in previous runs
6. Format a new Hadoop Distribtued File System (HDFS)
7. Start Hadoop daemons
8. Execute the map-reduce computation
9. Stop Daemons
10. Stop HDFS
Although the list is bit long, most of the tasks are straigt forward to perfom in a shell script.
The first problem I face is finding the IP addresses of the nodes. PBS passes this information via the variable PBS_NODEFILE. However, in a multi-core and multi-processor systems the PBS_NODEFILE contains multiple entries of the same node depending on the numebr of processors we requested in each node. So I have to find the "SET" of IP addresses eliminating the duplicates. Then have to update the configuration files depending on this information. So I decided to use a Java program to do the job (with my shell script knowledge I could not find an easy way to do a "SET" operation)
Once I have this simple Java file to perform the steps 1 -4 the rest is straightforward. Here is my PBS script and I the link after the script will show you the simple Java program which update the configuration files.
----------------------------------------------------------
#!/bin/bash
#PBS -l nodes=5:ppn=8
#PBS -l walltime=01:00:00
#PBS -N hdhep
#PBS -q hod
java -cp ~/hadoop_root/bin HadoopConfig $PBS_NODEFILE ~/hadoop-0.17.0/conf
for line in `cat $PBS_NODEFILE`;do
echo $line
ssh $line rm -rf /tmp/hadoop*
done
var=`head -1 $PBS_NODEFILE`
echo $var
ssh -x $var ~/hadoop-0.17.0/bin/hadoop namenode -format
ssh -x $var ~/hadoop-0.17.0/bin/start-dfs.sh
sleep 60
ssh -x $var ~/hadoop-0.17.0/bin/start-mapred.sh
sleep 60
ssh -x $var ~/hadoop-0.17.0/bin/hadoop jar ~/hadoop-0.17.0/hep.jar hep ~/hadoop_root /N/dc/scratch/jaliya/alldata 40 2
ssh -x $var ~/hadoop-0.17.0/bin/stop-mapred.sh
ssh -x $var ~/hadoop-0.17.0/bin/stop-dfs.sh
-------------------------------------------------------------------
[HadoopConfig.java]
As you can see in the script, I use ssh to log into each node of the cluster and perform the cleaning up of the HDFS directories. Then I use SSH to login to the master node to start the Hadoop daemons.
Next comes the actual execution of the data analysis task, which I have coded in the hep.jar.
After the MapReduce computation is over the rest of the commands simply stop the daemons.
This is method has more flexibility to the user and requires no changes for the batch job scheduling system. It also serves as an easy option when the number of MapReduce computations are smaller than the other batch jobs.
However, if the cluster is dedicated to run MapReduce computations, then everybody starting and stopping a HDFS file system does not make sense. Ideally the Hadoop should be started by the adminitrators and then the users should be allowed to simply execute the MapReduce computations on it.
Your comments are welcome!
We gave HOD a serious try but could not get it working the way we wanted. What we tried was to install HOD in set of nodes and let users to use it on demand via a job queue. This option simply did not work for multiple users, since the configurations options for the file system overlap between the users causing only one user to use Hadoop at a given time.
With this situation, I decided to give it a try to start Hadoop dynamically using PBS. The task the script should perform is as follows.
1. Identify the master node
2. Identify the slave nodes
3. Update $HADOOP_HOME/conf/masters and $HADOOP_HOME/conf/slaves files
4. UPdate the $HADOOP_HOME/conf/hadoop-site.xml
5. Cleanup any hadoop file system specific directories created in previous runs
6. Format a new Hadoop Distribtued File System (HDFS)
7. Start Hadoop daemons
8. Execute the map-reduce computation
9. Stop Daemons
10. Stop HDFS
Although the list is bit long, most of the tasks are straigt forward to perfom in a shell script.
The first problem I face is finding the IP addresses of the nodes. PBS passes this information via the variable PBS_NODEFILE. However, in a multi-core and multi-processor systems the PBS_NODEFILE contains multiple entries of the same node depending on the numebr of processors we requested in each node. So I have to find the "SET" of IP addresses eliminating the duplicates. Then have to update the configuration files depending on this information. So I decided to use a Java program to do the job (with my shell script knowledge I could not find an easy way to do a "SET" operation)
Once I have this simple Java file to perform the steps 1 -4 the rest is straightforward. Here is my PBS script and I the link after the script will show you the simple Java program which update the configuration files.
----------------------------------------------------------
#!/bin/bash
#PBS -l nodes=5:ppn=8
#PBS -l walltime=01:00:00
#PBS -N hdhep
#PBS -q hod
java -cp ~/hadoop_root/bin HadoopConfig $PBS_NODEFILE ~/hadoop-0.17.0/conf
for line in `cat $PBS_NODEFILE`;do
echo $line
ssh $line rm -rf /tmp/hadoop*
done
var=`head -1 $PBS_NODEFILE`
echo $var
ssh -x $var ~/hadoop-0.17.0/bin/hadoop namenode -format
ssh -x $var ~/hadoop-0.17.0/bin/start-dfs.sh
sleep 60
ssh -x $var ~/hadoop-0.17.0/bin/start-mapred.sh
sleep 60
ssh -x $var ~/hadoop-0.17.0/bin/hadoop jar ~/hadoop-0.17.0/hep.jar hep ~/hadoop_root /N/dc/scratch/jaliya/alldata 40 2
ssh -x $var ~/hadoop-0.17.0/bin/stop-mapred.sh
ssh -x $var ~/hadoop-0.17.0/bin/stop-dfs.sh
-------------------------------------------------------------------
[HadoopConfig.java]
As you can see in the script, I use ssh to log into each node of the cluster and perform the cleaning up of the HDFS directories. Then I use SSH to login to the master node to start the Hadoop daemons.
Next comes the actual execution of the data analysis task, which I have coded in the hep.jar.
After the MapReduce computation is over the rest of the commands simply stop the daemons.
This is method has more flexibility to the user and requires no changes for the batch job scheduling system. It also serves as an easy option when the number of MapReduce computations are smaller than the other batch jobs.
However, if the cluster is dedicated to run MapReduce computations, then everybody starting and stopping a HDFS file system does not make sense. Ideally the Hadoop should be started by the adminitrators and then the users should be allowed to simply execute the MapReduce computations on it.
Your comments are welcome!
High Energy Physics Data Analysis Using Hadoop and CGL-MapReduce
After the previous set of tests wtih parallel Kmeans clusting using CGL-MapReduce, Hadoop and MPI I shift the direction of testing to another set of tests. This time, the test is to process large number (and volume of) High Energy Physics data files and produce a histogram of interesting events. The amount of data that needs to be processed is 1 terabyte.
Converting this data analysis into a MapReduce version is straigt forward. First the data is split into managable chunks and each map task process some of these chunks and produce histograms of interested events. Reduce tasks merge the resulting histograms producing more concentrated histograms. Finally a merge operation combine all the histograms produced by the reduce tasks.
I performed the above test by incresing the data size on a fixed set of computing nodes using both CGL-MapReduce and Hadoop. To see the scalability of the MapReduce approach and the scalability of the two MapReduce implementations, I performed another test by fixing the amount of data to 100GB and varying the number of compute nodes used. Figure 1 and Figure 2 shows my findings.
 Figure 1. HEP data analysis, execution time vs. the volume of data (fixed compute resources)
Figure 1. HEP data analysis, execution time vs. the volume of data (fixed compute resources)
 Figure 2. Total time vs. the number of compute nodes (fixed data)
Figure 2. Total time vs. the number of compute nodes (fixed data)
Hadoop and CGL-MapReduce both show similar performance. The amount of data accessed in each analysis is extremely large and hence the performance is limited by the I/O bandwidth of a given node rather than the total processor cores. The overhead induced by the MapReduce implementations has negligible effect on the overall computation.
The results in Figure 2 shows the scalability of the MapReduce technique and the two implementations. It also shows how the performance increase obtained by the parallelism diminshes after a certain number of computation node for this particular data set.
Converting this data analysis into a MapReduce version is straigt forward. First the data is split into managable chunks and each map task process some of these chunks and produce histograms of interested events. Reduce tasks merge the resulting histograms producing more concentrated histograms. Finally a merge operation combine all the histograms produced by the reduce tasks.
I performed the above test by incresing the data size on a fixed set of computing nodes using both CGL-MapReduce and Hadoop. To see the scalability of the MapReduce approach and the scalability of the two MapReduce implementations, I performed another test by fixing the amount of data to 100GB and varying the number of compute nodes used. Figure 1 and Figure 2 shows my findings.
 Figure 1. HEP data analysis, execution time vs. the volume of data (fixed compute resources)
Figure 1. HEP data analysis, execution time vs. the volume of data (fixed compute resources) Figure 2. Total time vs. the number of compute nodes (fixed data)
Figure 2. Total time vs. the number of compute nodes (fixed data)Hadoop and CGL-MapReduce both show similar performance. The amount of data accessed in each analysis is extremely large and hence the performance is limited by the I/O bandwidth of a given node rather than the total processor cores. The overhead induced by the MapReduce implementations has negligible effect on the overall computation.
The results in Figure 2 shows the scalability of the MapReduce technique and the two implementations. It also shows how the performance increase obtained by the parallelism diminshes after a certain number of computation node for this particular data set.
Thursday, July 03, 2008
July 2nd Report
CGL MapReduce, Hadoop and MPI
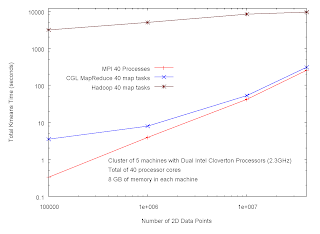 Figure 1. Performance of CGL MapReduce vs. Hadoop vs. MPI
Figure 1. Performance of CGL MapReduce vs. Hadoop vs. MPI
 Figure 2. Performance of CGL MapReduce vs. Hadoop vs. MPI vs. Java Threads
Figure 2. Performance of CGL MapReduce vs. Hadoop vs. MPI vs. Java Threads
More analyses will follow soon.
Last few weeks I was busy implementing CGL Map Reduce a streaming based map reduce implementation that uses a content dissemination network for all its communication. Our main objective behind this implementation is to avoid the overhead imposed by the technique adopted by both Google and Hadoop in their map-reduce implementations, that is communicate data via files.
Instead of communicating the data between the map and reduce tasks via files, we use NaradaBrokering's publish/subscribe messaging for the data transfer. In most of the map-reduce use cases the output of the map task is significantly smaller than the size of the input data. In addition, the use of a file system based data communication mechanism is prohibitively slow for Iterative map-reduce tasks such as clustering algorithms. These observations motivates us in implementing the CGL Map Reduce.
Following two graphs compares the performance of CGL MapReduce with other parallization techniques used for SPMD programs. For this benchmark we use kmeans algorithm to cluster a collection of 2D data points.
First we compare the performance of CGL MapReduce with Hadoop and MPI. We increase the size of the data set from 100000 points to 40 million and measured the total time for the computation under different implementations. MPI program was the fastest of the three while CGL MapReduce shows very close performance for large data sets. However, Hadoop's timing is almost 30 times longer than the CGL MapReduce and the MPI.
Following two graphs compares the performance of CGL MapReduce with other parallization techniques used for SPMD programs. For this benchmark we use kmeans algorithm to cluster a collection of 2D data points.
First we compare the performance of CGL MapReduce with Hadoop and MPI. We increase the size of the data set from 100000 points to 40 million and measured the total time for the computation under different implementations. MPI program was the fastest of the three while CGL MapReduce shows very close performance for large data sets. However, Hadoop's timing is almost 30 times longer than the CGL MapReduce and the MPI.
 Figure 1. Performance of CGL MapReduce vs. Hadoop vs. MPI
Figure 1. Performance of CGL MapReduce vs. Hadoop vs. MPINext, we performed the similar computation on a Single multi-core machine to see the effect of various parallelization techniques for this type of computations. Java threads, MPI and CGL MapReduce shows the converging results for large data sizes. In this case the main limitation factor is the memory access and hence the technique with minimum overhead to the to memory wins the battle. In our experiment the MPI performed the fastest and the Java threads performed second while CGL MapReduce is little behind Java threads. Again, Hadoop is about 30 times slower than any of the other programs.
MPI program achieves its performance from its C++ roots. Java threads is faster than CGL MapReduce simply due to the additional overheads in the map reduce implementation. Hadoop's slowness is due to its overhead in creating and retrieving files for the communication.
MPI program achieves its performance from its C++ roots. Java threads is faster than CGL MapReduce simply due to the additional overheads in the map reduce implementation. Hadoop's slowness is due to its overhead in creating and retrieving files for the communication.
 Figure 2. Performance of CGL MapReduce vs. Hadoop vs. MPI vs. Java Threads
Figure 2. Performance of CGL MapReduce vs. Hadoop vs. MPI vs. Java ThreadsMore analyses will follow soon.
Friday, May 23, 2008
May 21st Report - CTS Conference
Last two weeks, i was preparing for the cts 2008 conference. I had to prepare for my talk and the demonstration. I had to struggle with the new Dell laptop to get the demo working, simply because of the incompatibilities in the software and the necessary drivers. After tweaking some configurations, I was able to install Fedora 7 and ROOT. However, the demo started giving some unpredictable behaviors.
The conference went well, did my talk and did the demonstration as well, the demo crashes few times though.
During the conference, the power went off for the Irvine area and we had to stay without power for almost 16 hours. The organization committee worked hard to get the conference going with some emergency power, and the speakers had to shout the audience since we did not have power for the audio equipments.
After all, it is a very fruitful experience for me. My first talk in a large conference. The keynote speeches and the panel discussions brought a lot of insight into the future of the Collaborative Technologies.
Here are the slides for my presentation.
The conference went well, did my talk and did the demonstration as well, the demo crashes few times though.
During the conference, the power went off for the Irvine area and we had to stay without power for almost 16 hours. The organization committee worked hard to get the conference going with some emergency power, and the speakers had to shout the audience since we did not have power for the audio equipments.
After all, it is a very fruitful experience for me. My first talk in a large conference. The keynote speeches and the panel discussions brought a lot of insight into the future of the Collaborative Technologies.
Here are the slides for my presentation.
Tuesday, May 13, 2008
A ROOT bug when using DLLs
I have been trying to convert the ROOT & C++ program that extends the NaradaBrokering's publish/subscribe functionalities to ROOT users to Windows. I was able to convert the pure C++ part of it and the DLL works fine in Windows.
Then I tried to use the wrappers for ROOT with the generated dictionary. Code generation and the compilation all worked as expected but when I try the DLL the ROOT crashes printing garbage characters.
I track down the problem for two days and was able to reduce the problem into its minimum form.
It simply boils down to a parameter passing problem related to string values.
I then ask the question from the ROOT Talks and one of the ROOT devs, Bertrand, helped me to track down it further.
Finally, the resolution is a bug in ROOT 5.19.02. From my experiments, I know that it was also present in ROOT 5.18 as well.
Here is the full resolution in the ROOT Talk.
http://root.cern.ch/phpBB2/viewtopic.php?p=27702#27702
According to Bertrand, there will be a new release tomorrow and the bug seemed to be fixed in this release.
Hope it will fix my problem and also no more bugs in my way :))
Then I tried to use the wrappers for ROOT with the generated dictionary. Code generation and the compilation all worked as expected but when I try the DLL the ROOT crashes printing garbage characters.
I track down the problem for two days and was able to reduce the problem into its minimum form.
It simply boils down to a parameter passing problem related to string values.
I then ask the question from the ROOT Talks and one of the ROOT devs, Bertrand, helped me to track down it further.
Finally, the resolution is a bug in ROOT 5.19.02. From my experiments, I know that it was also present in ROOT 5.18 as well.
Here is the full resolution in the ROOT Talk.
http://root.cern.ch/phpBB2/viewtopic.php?p=27702#27702
According to Bertrand, there will be a new release tomorrow and the bug seemed to be fixed in this release.
Hope it will fix my problem and also no more bugs in my way :))
Sunday, May 11, 2008
May 7th Report
Posters for the CTS Conference
I have created two posters for the CTS 2008 conference. After a week of crash learning Adobe Illustrator I was able to create them in the way I need :)
Here are the two posters.

I have created two posters for the CTS 2008 conference. After a week of crash learning Adobe Illustrator I was able to create them in the way I need :)
Here are the two posters.


Wednesday, April 16, 2008
Hadoop Presentation
Today I did a small presentation on Apache Hadoop
I went though the documentation they have on HDFS, Map-reduce framework, and the Streaming API. I also had to go through the code to understand some of the functionalities in the framework. So far my idea is that the framework is bit more biased towards the text oriented computations. Probably because the initial computations that they use map-reduce are mainly centered on processing large collection of documents (specifically web pages)
Here is my presentation
I went though the documentation they have on HDFS, Map-reduce framework, and the Streaming API. I also had to go through the code to understand some of the functionalities in the framework. So far my idea is that the framework is bit more biased towards the text oriented computations. Probably because the initial computations that they use map-reduce are mainly centered on processing large collection of documents (specifically web pages)
Here is my presentation
Friday, April 11, 2008
April 9th Report
Platform shift for the NBC++ Bridge (Linux to Windows)
The HEP solution is taking a new turn by moving on to CherryPy and Windows. This impose a new requirement for the NaradaBrokering's C++ bridge I wrote.
Initially I did the development in Linux platform using g++ compiler. With the new requirement, I had to compile this for Windows based platforms.
Dr. Julian Bunn gave a big help by converting the C++ bridge to a DLL for windows. After doing some debugging, I was able to get NBC++ working on Windows. Another dimension for NaradaBrokering users.
Since it is hard to maintain two code repositories (one for Windows and one for Linux), I decided to merge the two source code repositories. After covering the differences with pre-compiler directives I was able to get the same code working in both Windows and Linux.
Have to finish the documentation and then I can release the new version of NBC++ soon.
The HEP solution is taking a new turn by moving on to CherryPy and Windows. This impose a new requirement for the NaradaBrokering's C++ bridge I wrote.
Initially I did the development in Linux platform using g++ compiler. With the new requirement, I had to compile this for Windows based platforms.
Dr. Julian Bunn gave a big help by converting the C++ bridge to a DLL for windows. After doing some debugging, I was able to get NBC++ working on Windows. Another dimension for NaradaBrokering users.
Since it is hard to maintain two code repositories (one for Windows and one for Linux), I decided to merge the two source code repositories. After covering the differences with pre-compiler directives I was able to get the same code working in both Windows and Linux.
Have to finish the documentation and then I can release the new version of NBC++ soon.
Thursday, February 28, 2008
February 27th Report
Writing Papers
The paper, A Collaborative Framework for Scientific Data Analysis and Visualization, I submitted to CTS2008 got accepted. However, reviewers pointed out that there are some grammatical errors in my writing. I had to correct these errors within a week because of the final submission deadline. The following section highlights my experience with the above.
Dr. Shrideep Pallickara pointed me to two books.
1. The Elements of Style by William Strunk Jr. and E.B. White.
2. The Chicago Manual of Style by University of Chicago Press Staff
I found both books in the bookstore and noticed that the second one is more suitable as a reference. The first one is a really nice book for my situation. It is very small book (~100 pages) but it has lot of grammatical styles with examples in it.
I was able to fix lot of grammatical errors present in my initial write up with the help of the above book.
Still I was not 100% sure about my corrections, and decided to search for a proof read service. I found many online services, which does proof reading. However, all of them charge very high amounts for quick jobs.
Lucy Buttersbry, the secretary of our department, pointed me to Writing Tutorial Services in Ballantine Hall 206 (855-6738). If you are an IU student, this is a very good service. They will not proof read your papers, but will help you to identify the common errors you made by going through the paper.
I showed up my revised paper to one of the instructors and he showed me few more common errors that I had in my writing.
After all these steps and few more review cycles I was able to come up with the final version of the paper.
Formatting the Paper
I did the initial writing on Microsoft Word and converted it to pdf before submitting. After converting the document to pdf, I noticed that the column width(for two column pages) of the pdf document is smaller than the column width expected by the conference format sheet.
I decided to give it a try with the Latex format sheet that they provide. After copying few pages I noticed that the column width is correct and also the length of the paper is slightly reduced when formatted using Latex. Of course, the neatness is superb as well.
At the beginning I found it bit hard to insert figures, but it is simply a matter of finding the (right) easy method of doing it. It is very easy to insert images as pdf files. So the only change I had to do was to convert the png images I had into pdf files. I could easily do that using the CutePDF writer. The following latex section shows how I include figures.
\begin{figure}[h]
\begin{center}
\includegraphics[width=0.46\textwidth]{D:/Academic/Ph.D/CTS2008/architecture2.pdf}
\textbf{\caption{\centering{Architecture of the Proposed Collaborative Data Analysis Framework}}
\label{fig:arch}}
\end{center}
\end{figure}
One final thought. If you have time, better to format the paper using Latex as it save you space as well as provide a very neat paper.
The paper, A Collaborative Framework for Scientific Data Analysis and Visualization, I submitted to CTS2008 got accepted. However, reviewers pointed out that there are some grammatical errors in my writing. I had to correct these errors within a week because of the final submission deadline. The following section highlights my experience with the above.
Dr. Shrideep Pallickara pointed me to two books.
1. The Elements of Style by William Strunk Jr. and E.B. White.
2. The Chicago Manual of Style by University of Chicago Press Staff
I found both books in the bookstore and noticed that the second one is more suitable as a reference. The first one is a really nice book for my situation. It is very small book (~100 pages) but it has lot of grammatical styles with examples in it.
I was able to fix lot of grammatical errors present in my initial write up with the help of the above book.
Still I was not 100% sure about my corrections, and decided to search for a proof read service. I found many online services, which does proof reading. However, all of them charge very high amounts for quick jobs.
Lucy Buttersbry, the secretary of our department, pointed me to Writing Tutorial Services in Ballantine Hall 206 (855-6738). If you are an IU student, this is a very good service. They will not proof read your papers, but will help you to identify the common errors you made by going through the paper.
I showed up my revised paper to one of the instructors and he showed me few more common errors that I had in my writing.
After all these steps and few more review cycles I was able to come up with the final version of the paper.
Formatting the Paper
I did the initial writing on Microsoft Word and converted it to pdf before submitting. After converting the document to pdf, I noticed that the column width(for two column pages) of the pdf document is smaller than the column width expected by the conference format sheet.
I decided to give it a try with the Latex format sheet that they provide. After copying few pages I noticed that the column width is correct and also the length of the paper is slightly reduced when formatted using Latex. Of course, the neatness is superb as well.
At the beginning I found it bit hard to insert figures, but it is simply a matter of finding the (right) easy method of doing it. It is very easy to insert images as pdf files. So the only change I had to do was to convert the png images I had into pdf files. I could easily do that using the CutePDF writer. The following latex section shows how I include figures.
\begin{figure}[h]
\begin{center}
\includegraphics[width=0.46\textwidth]{D:/Academic/Ph.D/CTS2008/architecture2.pdf}
\textbf{\caption{\centering{Architecture of the Proposed Collaborative Data Analysis Framework}}
\label{fig:arch}}
\end{center}
\end{figure}
One final thought. If you have time, better to format the paper using Latex as it save you space as well as provide a very neat paper.
Monday, February 04, 2008
February 13th Report
Demonstration to Prof Malcolm Atkinson.
Prof Malcolm Atkinson is the Director of The e-Science Institute and e-Science Envoy National e-Science Centre and was visiting our lab on 4th of February. The lab has organized a demo session so that most students can show their work to him.
When I got the mail regarding the demo, I was in the middle of modifying the ROOT-NB-Clarens application(my research prototype) to add new features. After two long days I was able to get it working and today we did the demo successfully.
Prof Malcolm Atkinson is the Director of The e-Science Institute and e-Science Envoy National e-Science Centre and was visiting our lab on 4th of February. The lab has organized a demo session so that most students can show their work to him.
When I got the mail regarding the demo, I was in the middle of modifying the ROOT-NB-Clarens application(my research prototype) to add new features. After two long days I was able to get it working and today we did the demo successfully.
January 30th Report
Two papers were due during these and had to struggle with time to get those two papers completed before the deadline.
Followings are the conferences:
I also created a research page which highlights the motivation , goals and the proposed solution of my research. I looking forward to maintain that web site throughout my Ph.D. research.
Followings are the conferences:
- The 2008 International Symposium on Collaborative Technologies and Systems (CTS 2008)
- 2008 IPDPS TCPP PhD Forum
I also created a research page which highlights the motivation , goals and the proposed solution of my research. I looking forward to maintain that web site throughout my Ph.D. research.
Wednesday, January 16, 2008
January 16th Report
Root Client Supports Shared Eventing and Shared Display Type Collaborations.
So far the HEP Data Analysis Client that we have uses a shared event model for collaboration. All the clients perform the fitting and merging of histograms received from servers. This is a very useful feature if different collaborative clients need to "fit" different models to the data received to them. However, if the same model is used by all the clients, then a shared display type collaboration would be the right solution.
I added a feature to the client so that it publishes its current histogram as an image (after fitting and merging) to a topic using the NB's C++ client. I also developed a separate program to simply subscribe to a topic and display the images received over the pub/sub communication channel. This program is very lightweight as its task is merely showing images in a canvas as an when they are received.
This implementation enables the shared display type collaboration among the participating clients to an experiment. Physicists who just need to see the results of an experiment can simply use the shared display client.
Currently all the clients subscribed to a particular topic will receive the histogram images. However, with the introduction of the "agents" , which keep track of on going experiments, to the system these settings can be controlled.
So far the HEP Data Analysis Client that we have uses a shared event model for collaboration. All the clients perform the fitting and merging of histograms received from servers. This is a very useful feature if different collaborative clients need to "fit" different models to the data received to them. However, if the same model is used by all the clients, then a shared display type collaboration would be the right solution.
I added a feature to the client so that it publishes its current histogram as an image (after fitting and merging) to a topic using the NB's C++ client. I also developed a separate program to simply subscribe to a topic and display the images received over the pub/sub communication channel. This program is very lightweight as its task is merely showing images in a canvas as an when they are received.
This implementation enables the shared display type collaboration among the participating clients to an experiment. Physicists who just need to see the results of an experiment can simply use the shared display client.
Currently all the clients subscribed to a particular topic will receive the histogram images. However, with the introduction of the "agents" , which keep track of on going experiments, to the system these settings can be controlled.
Subscribe to:
Posts (Atom)

